数据库的索引 数据库IO B+树
MySQL中的page,IO和索引
概念
MySQL的IO
而 MySQL 作为一款应用软件,可以想象成一种特殊的文件系统。它有着更高的IO场景.
为了更好的进行IO操作, MySQL 服务器在内存中运行的时候,在服务器内部,就申请了被称为
Buffer Pool的的大内存空间(可以在配置文件中找到),来进行各种缓存。其实就是很大的内存空间,来和磁盘数据进行IO交互。提高效率,要尽量减少系统和磁盘的IO次数。
MySQL InnoDB引擎 使用 16KB 进行IO交互。这个基本数据单元,在 MySQL 这里叫做page。(注意和系统的page区分)
- MySQL需要管理所有的
page。当数据库需要读取数据页时,首先会检查该页是否已经在Buffer Pool中。如果在,称为命中缓存,数据库直接从内存中读取数据,速度非常快。如果不在,则需要从磁盘读取,并将数据页缓存到 Buffer Pool 中。- 在
Buffer Pool中,page以双向链表的形式被管理。
- 在
索引的基本概念
索引(Index)是在数据库中用于加速数据检索的一种数据结构。索引的存在可以显著提高查询性能,特别是在涉及大量数据的复杂查询时。
- 类似书籍的目录:索引就像书籍的目录,通过查找目录中的关键词,快速找到相关内容的页面。在数据库中,索引的作用类似,帮助快速定位数据的位置,而无需扫描整个表。
- 空间换时间。
加速查询:当你在查询中使用索引列作为条件时,数据库可以直接通过索引找到匹配的行,而不需要遍历所有数据,从而提高查询效率。
索引和page
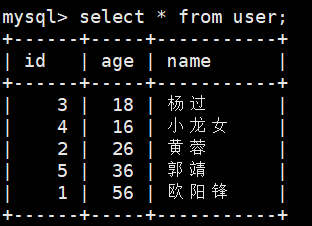
当我们向有主键的表中插入数据的时候,会进行自动的排序。因为只有有序了,才能进行页内目录。
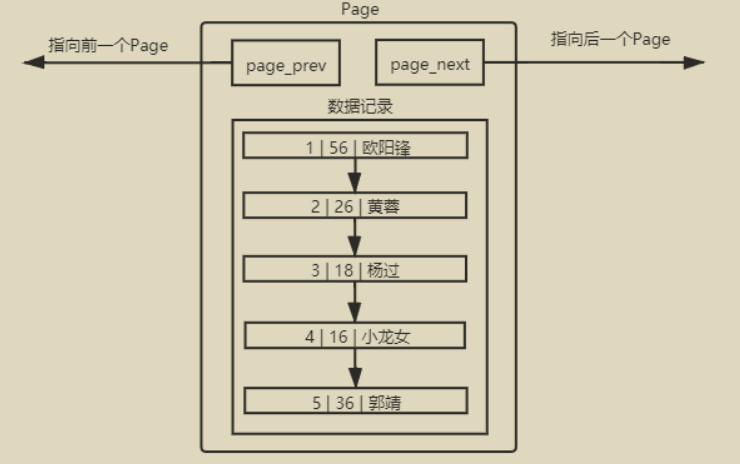
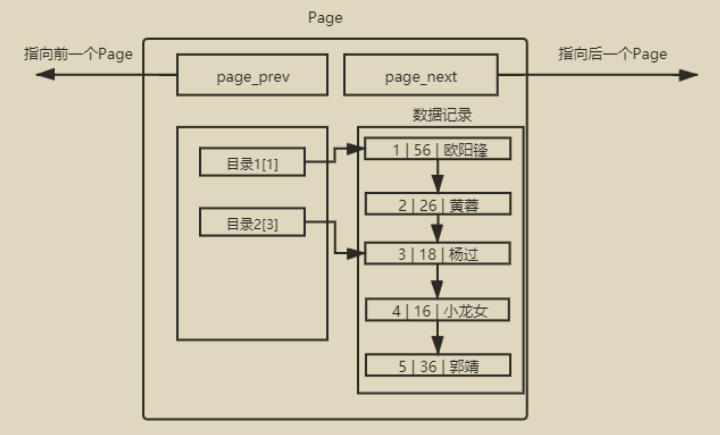
单表数据不断被插入的情况下, MySQL会在容量不足的时候,自动开辟新的Page来保存新的数据,然后通过指针的方式,将所有的Page组织起来。但是我们如果仅仅是普通的将这些page线性连接起来的话,那么在查找的时候,还是需要逐个遍历page。因此,我们需要给page也添加目录。
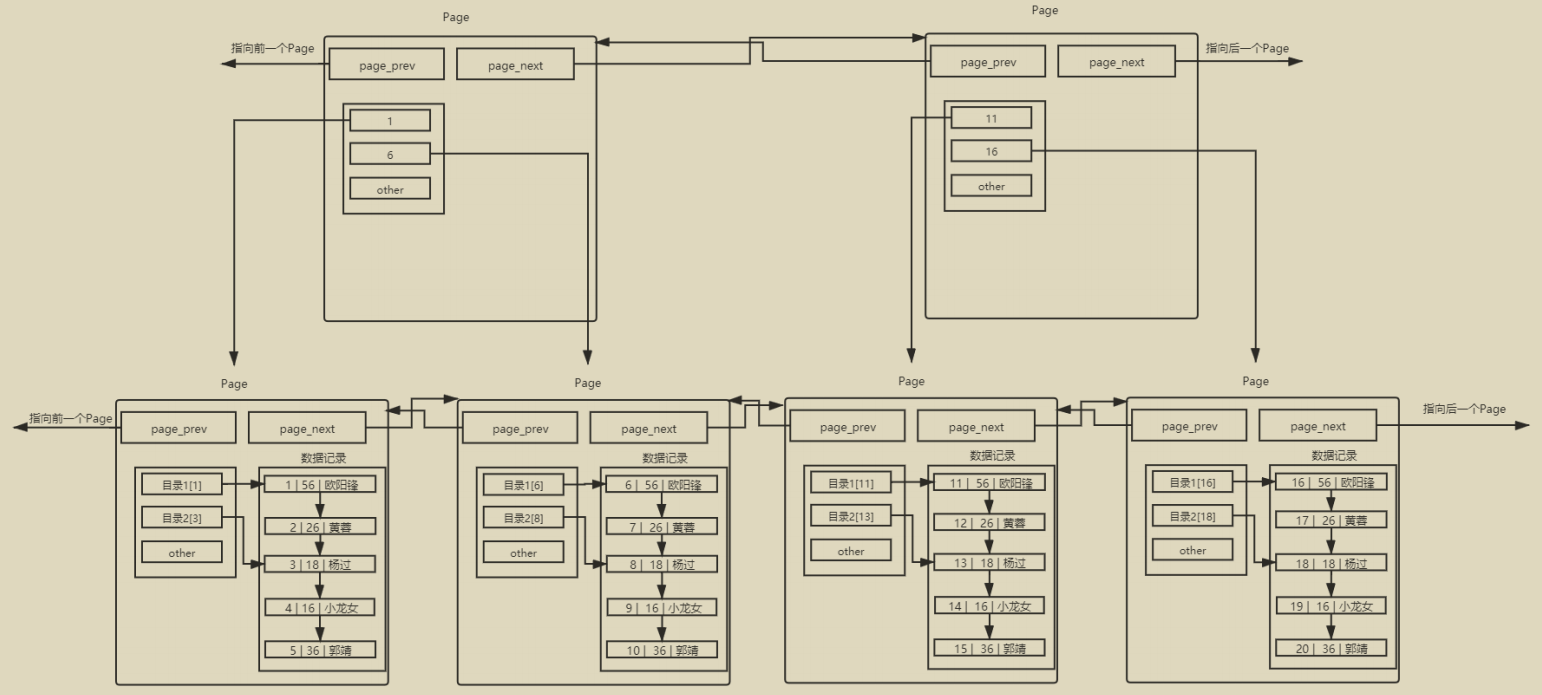
同样的逻辑,我们可以增加这颗树的高度——如此的数据结构,我们可以称为B+树。
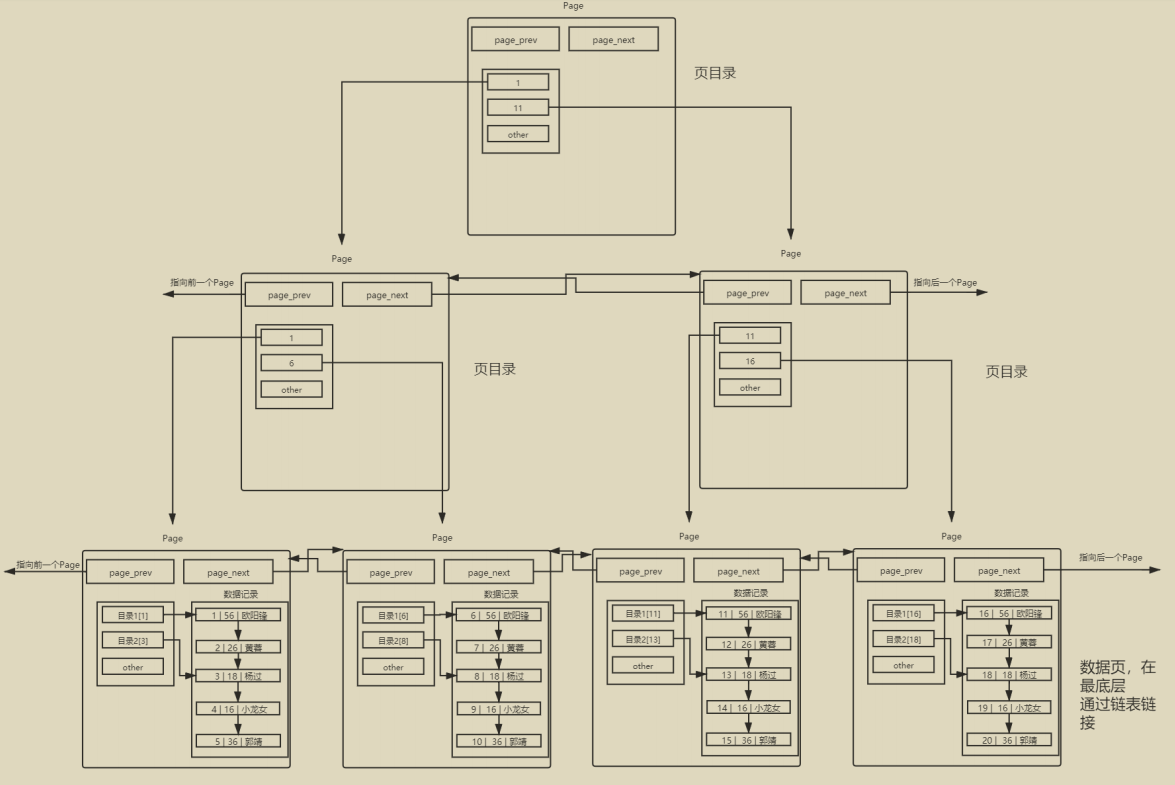
B+树
每一个节点(
page)都有目录项,可以大大提高搜索效率—— 因为减少了途径的节点数量(IO次数)。- 需要保持
矮胖的特点——减少找到叶子节点途径的节点的数量,并提高可以查找叶子节点数量。
- 需要保持
只有叶子节点保有数据,其余节点只保存目录项,因此可以存储更多的
目录项。叶子节点使用全部链表级联起来。这是B+树的特点,好处是提高了我们在确定区间的范围内进行查找的效率——只要找到起点和终点,就可以直接用链表查看数据。
Hash就不擅长范围查找。
即使我们的表没有自定义主键,MySQL也会生成一个隐式的主键,并以此主键构建
B+树。
为何不选择B树?
B+叶子节点,全部相连,而B没有。叶子节点相连,更便于进行范围查找。
B+树节点不存储data,这样一个节点就可以存储更多的key。可以使得树更矮,所以IO操作次数更少。
索引的类型
1. 聚簇索引
定义:聚簇索引是一种数据存储方式,其中数据表的实际数据行按索引的顺序存储。每张表最多只能有一个聚簇索引,因为数据本身只能按照一种顺序进行排序和存储。
存储结构:在有聚簇索引的表中,数据页按照索引的键值顺序存储,因此索引的叶节点就是数据页。可以理解为,数据和索引是“聚合”在一起的。
示例:在 MySQL 的 InnoDB 存储引擎中,主键索引就是一种聚簇索引。如果没有定义主键,InnoDB 会选择一个唯一的非空索引作为聚簇索引。如果都没有,InnoDB 会自动生成一个隐藏的聚簇索引。
优点:
- 数据访问速度快:由于数据按照索引顺序存储,查询时可以直接访问数据,无需二次查找。
- 范围查询效率高:由于数据是按顺序存储的,范围查询时不需要额外的排序操作。
缺点:
- 插入速度慢:因为数据需要按顺序插入,插入新数据时可能需要移动现有数据。
- 更新和删除操作较慢:如果需要调整数据的存储顺序,也会影响性能。
2. 非聚簇索引,回表操作
定义:非聚簇索引是一种独立于数据存储的索引结构。非聚簇索引的叶节点存储的是指向数据的指针(即行标识符或主键值),而不是实际的数据本身。
存储结构:非聚簇索引的叶节点包含指向表中数据的指针,而数据本身仍然按照聚簇索引(或表的默认顺序)存储。因此,一个表可以有多个非聚簇索引。
示例:假设在一个包含学生信息的表
students中,创建了一个name列的非聚簇索引。那么该索引的叶节点将存储name和对应数据行的指针,而实际数据行仍然按主键或其他顺序存储。优点:
- 多个索引:一个表可以有多个非聚簇索引,有助于加速不同类型的查询。
- 灵活性:非聚簇索引不会影响数据的物理存储顺序,因此在创建、修改或删除索引时对数据表的影响较小。
缺点:
- 数据访问速度较慢:因为叶节点存储的是指针,查询时需要先通过索引找到指针,然后再去数据页查找实际数据(称为“回表”操作)。
- 存储空间大:由于指针需要额外的存储空间,非聚簇索引通常比聚簇索引占用更多的磁盘空间。
MySQL 中有几种常见的索引类型:
PRIMARY KEY 索引:
- 每个表只能有一个主键索引。
- 主键索引不仅唯一,还会自动创建索引。
- 数据库会使用主键索引加速基于主键的查询。
UNIQUE 索引:
- 确保索引列中的值是唯一的,不能有重复值。
- 一个表可以有多个唯一索引。
- 在插入数据时,数据库会检查唯一性,防止重复值。
普通索引(INDEX):
- 最常见的索引类型,用于加速常见的查询。
- 可以在一个表上创建多个普通索引。
全文索引(FULLTEXT INDEX):
- 专用于全文搜索,加速文本字段上的关键字查询。
- 常用于大文本字段(如
TEXT类型)上的全文检索。
组合索引(Composite Index):
- 一个索引包含多个列,用于加速涉及多列的查询。
- 在查询中使用多列作为条件时,组合索引可以显著提升性能。
索引的优缺点
优点:
- 加速查询:索引可以极大地提高数据检索速度,特别是在大数据集上。
- 提高排序效率:使用索引可以更快速地进行数据排序操作。
- 加速聚合操作:如
COUNT()、MAX()、MIN()等操作时,索引可以帮助更快地找到结果。
缺点:
- 占用空间:索引会占用额外的磁盘空间,特别是大量数据和多个索引时,空间占用显著。
- 影响写操作:插入、更新和删除操作可能会因为需要维护索引而变慢。
- 维护成本:创建和维护索引需要额外的系统开销。
索引的增删查改
在 MySQL 中,索引的增删查改操作是非常常见的数据库管理任务。这些操作可以通过 SQL 语句来实现。以下是如何实现索引的增删查改的详细说明和示例:
1. 添加索引(增)
添加索引可以通过 CREATE INDEX 或 ALTER TABLE 语句来实现。
使用 CREATE INDEX 语句
1 | |
index_name对应查看索引时的key_name。
使用 ALTER TABLE 语句
1 | |
示例:
假设我们有一个表 students,要在 name 列上添加索引:
1 | |
2. 删除索引(删)
删除索引可以使用 DROP INDEX 或 ALTER TABLE 语句。
使用 DROP INDEX 语句
1 | |
使用 ALTER TABLE 语句
1 | |
示例:
要删除 students 表上名为 idx_name 的索引:
1 | |
3. 查询索引(查)
要查看一个表上的所有索引,可以使用 SHOW INDEX 语句。
使用 SHOW INDEX 语句
1 | |
示例:
要查看 students 表上的所有索引:
1 | |
4. 修改索引(改)
索引本身无法直接修改,但可以通过删除旧索引并创建新索引来实现索引的修改。
示例:
假设我们要修改 students 表上 idx_name 索引,使其索引 name 列的前 10 个字符(适用于长文本列的前缀索引):
删除旧索引:
1
DROP INDEX idx_name ON students;创建新索引:
1
CREATE INDEX idx_name ON students(name(10));
创建索引的原则
索引应创建在频繁作为查询条件的字段上,因为索引能够加速查询。
唯一性太差的字段(例如布尔值或性别)不适合单独创建索引,因为它们无法显著减少扫描的行数。
更新频繁的字段不适合创建索引,因为索引的维护会增加写操作的开销。
不出现在查询条件中的字段不应创建索引,因为它们不会带来查询性能的提升。
复合索引
定义:复合索引是指在数据库中由多个列(字段)组合在一起的索引。它不同于单列索引,它可以在一个索引中包含多列字段。
作用:复合索引可以加速多列查询的速度。与为多个字段分别创建单列索引相比,复合索引通常能提供更好的性能,特别是在涉及多个条件的查询中。
示例:
1
CREATE INDEX idx_name_age ON users (name, age);该语句创建了一个
name和age字段上的复合索引。如果查询语句同时包含name和age作为条件,数据库将能够更快地找到结果。注意事项:复合索引的字段顺序很重要,通常应该把选择性更高的列(即能更大程度区分数据的列)放在前面。
索引最左匹配原则
定义:索引最左匹配原则是指在使用复合索引时,MySQL 会遵循从左到右的顺序依次匹配查询条件中的字段。索引查询会一直向右匹配,直到遇到范围查询(如
<、>、BETWEEN、LIKE)为止,然后停止匹配。- 也因此B-Tree 的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。(招银网络笔试)
原理:当使用复合索引时,只有从索引的最左边开始匹配,MySQL 才会利用该索引进行查询优化。如果跳过了某个字段,后面的字段即使在索引中也不会被使用。
示例:
假设有一个复合索引idx_name_age_city创建在name、age和city列上:1
CREATE INDEX idx_name_age_city ON users (name, age, city);最左匹配的情况:
1
2
3SELECT * FROM users WHERE name = 'John';
SELECT * FROM users WHERE name = 'John' AND age = 25;
SELECT * FROM users WHERE name = 'John' AND age = 25 AND city = 'New York';以上查询语句都能利用
idx_name_age_city这个索引,因为它们都从最左边的name开始匹配。非最左匹配的情况:
1
SELECT * FROM users WHERE age = 25 AND city = 'New York';上述查询不会使用
idx_name_age_city索引,因为它跳过了最左边的name列。MySQL 无法利用这个索引进行优化。
索引覆盖
定义:索引覆盖是指查询所需要的所有数据都能从索引中获取,而不需要回表(即不需要再访问实际的数据行)。这样的查询称为覆盖索引查询(Covering Index Query)。
优点:索引覆盖可以显著提高查询性能,因为查询引擎可以直接从索引中获取所需的数据,而不必再去磁盘上读取数据行,从而减少了 I/O 操作。
示例:
假设有以下复合索引:1
CREATE INDEX idx_name_age ON users (name, age);下面的查询可以使用索引覆盖:
1
SELECT name, age FROM users WHERE name = 'John';所有需要的数据(
name和age)都可以从idx_name_age索引中获得,因此查询可以完全在索引中完成,不需要回表。