高性能内存池
内存池项目过程中的一些重点
项目GitHub地址
对象池(定长内存池)
- 定长:存储内容的大小是不变的。
1.如何将一段连续的空间的前几个字节单独赋予一个指针值
使用强转可以将前几个字节提出来。
由于不同操作系统的
指针大小可能不同,我们可以使用二级指针来准确的指针大小。
1 | |
2. 对于申请的对象大小至少为一个指针的大小,便于使用链表回收。
3. *(void**)可以刚好取出一个指针大小的空间。
什么是内存碎片?
- 内存碎片是指在计算机内存管理中,内存被频繁分配和释放后,出现了大量的小块未被使用的内存区域,这些小块内存虽然总量上足够分配新的内存请求,但因为分散而无法满足较大连续内存需求的现象。
内存碎片类型
- 外部碎片:
- 发生在堆内存(动态内存)中,是指内存中存在许多空闲块,但由于它们不是连续的,无法满足较大的内存分配请求。
- 内部碎片:
- 发生在分配的内存块内部,是指分配的内存比实际需要的要大,多余的部分无法被使用或回收,导致浪费。
性能测试结果如下:
- 在数据量仅为
3*10^5时,性能提升就十分明显。(Release 模式)
内存池
组成:
Thread Cache(无锁)
- 每个线程独有的缓存,用于小于256KB的内存分配。
- 线程直接从此缓存申请内存,无需加锁,提升并发效率。
实现:
多个进程的自由链表,根据每个进程对内存的需求不同从而匹配大小不同的链表。因为我们不能给所有大小都设置一个自由链表。而是梯度的设置自由链表。
对于每一种大小的线程,为了能将他们统一的存储起来,因此需要为它们需要引入对齐规则。
- 因为对齐规则的存在,可能存在一定程度的内存浪费——内部碎片。
- 如果对齐粒度过细,则可能会导致链表节点数过多。
- 线程如何获取到
thread cache?需要使用TLS,即——线程局部存储。thread cache是线程独享,无锁的重要原因的,并在该线程内具有全局可见性。(不同于常规的全局变量)
| 字节大小范围 | 对齐数 | 对应哈希桶范围 |
|---|---|---|
[1, 128] |
8 byte 对齐 | freelist[0, 16) |
[129, 1024] |
16 byte 对齐 | freelist[16, 72) |
[1025, 8 * 1024] |
128 byte 对齐 | freelist[72, 128) |
[8 * 1024 + 1, 64 * 1024] |
1024 byte 对齐 | freelist[128, 184) |
[64 * 1024 + 1, 256 * 1024] |
8 * 1024 byte 对齐 | freelist[184, 208) |
运作过程
申请内存:
当内存申请
size<=256KB,先获取到线程本地存储的thread cache对象,计算size映射的哈希桶自由链表下标i。如果自由链表
_freeLists[i]中有对象,则直接Pop⼀个内存对象返回。如果
_freeLists[i]中没有对象时,则批量从central cache中获取⼀定数量的对象,插入到自由链表并返回⼀个对象。
释放内存:
当释放内存小于256k时将内存释放回
thread cache,计算size映射自由链表桶位置i,将对象Push
到_freeLists[i]。当链表的长度过长,则回收⼀部分内存对象到
central cache。
Central Cache(桶锁)
所有线程共享的缓存,Thread Cache 按需从 Central Cache 获取对象。
为了所有线程都可以访问到
Central Cache,设计**饿汉单例模式**。span,以页为单位的大块内存。只不过它内部仍然被切分为了和Thread Cache类似的小块内存。
Central Cache适时回收Thread Cache中的对象,避免单线程占用过多内存,保证多个线程之间的内存分配更均衡。由于存在竞争,获取对象需要加锁,但通过桶锁和较少的访问频率降低竞争激烈程度。
- 竞争:如果当线程1和线程2的自由链表都使用完后,他们都向
Central Cache索要内存,但索要的都是Central Cache的同一个桶,那么就会发生竞争。
- 竞争:如果当线程1和线程2的自由链表都使用完后,他们都向
慢开始(慢增长)反馈调节算法
1 | |
作用:
一开始
MaxSize()返回值为1并递增,随着索要次数的增加,每次分配的数量batchNum也增多,最后最多达到NumMoveSize(size) —— 其能够根据对象大小计算合适的分配数量。可以调节分配数量的增长速度。
条件编译分别64/32位机器
两者的页数量不同,64位环境下可能需要unsigned long long来存储。
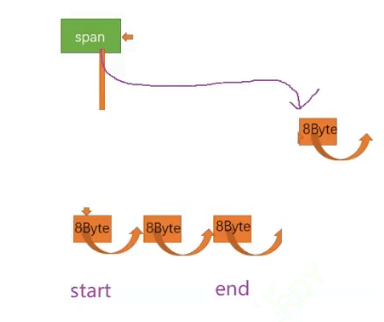
如何取出一段长度为n区间的freeList空间?
将end从start位置开始,往后移动n-1,然后将span的freeList指向end->next,最后将end置为nullptr,返回start。
运作过程
整理后的说明如下:
申请内存
从 Central Cache 获取内存对象:
当 thread cache 中没有足够的内存时,它会批量向 central cache 申请内存对象。这个批量获取的数量采用类似于网络 TCP 协议中的拥塞控制的慢启动算法。
Central cache 使用一个哈希映射的 spanlist 来管理内存分配。spanlist 中挂载着 span 对象,thread cache 会从 span 中提取内存对象。这个过程中需要加锁,不过为了提高效率,这里使用的是桶锁。
从 Page Cache 获取新的 Span:
- 如果 central cache 中的 spanlist 内的所有 span 都没有可用的内存,则需要向 page cache 申请一个新的 span 对象。获取到新的 span 后,将其管理的内存按大小切分,并将这些内存块链接为自由链表,然后从中分配内存对象给 thread cache。
Span 的 use_count 记录:
- 每当 central cache 中的 span 向 thread cache 分配一个对象时,span 的 use_count 值会增加。当分配完成后,use_count 用来记录已分配的对象数量。
释放内存
将内存释放回 Central Cache:
当 thread cache 中的内存使用过多或线程销毁时,会将内存释放回 central cache。在释放内存时,span 的 use_count 值会减少。当 use_count 减少到 0 时,表示所有对象都已归还给 span,此时 span 会被释放回 page cache。
Page cache 会将相邻的空闲页合并,减少内存碎片。
如何判断
ThreadCache归还的内存要给哪一个span?- 根据要归还的地址,找到对应的映射关系,最后找到对应的页号。
如何划分Central Cache的空间?
- 计算改内存的起始,结束地址。
1 | |
- 根据对象大小进行划分。
1 | |
Page Cache
位于整个内存池结构的底部, 作为Central Cache 上层的缓存,以页为单位存储和分配内存。
当 Central Cache 缺少对象时,Page Cache 提供一定数量的页,切割为固定大小的小块内存分配给 Central Cache。
- 依然是饿汉方式实现的单例模式。
回收和合并相邻的页,减少内存碎片问题。
直接定址法的哈希桶
- 需要几页的
page,就去第几个桶索要。- 里如果我需要两页,那么我就去第二个桶索要内存。
每次扩容的时候,只需要向堆申请第128个桶的对象即可
因为Page Cache的
第128个桶,对应Central Cache需要128页。而Central Cache需要128页又可以拆分为Central Cache需要124页和Central Cache需要4页,以此类推。上述的逆过程,就是Page Cache的合并,从而解决内存碎片问题。
当向
Page Cache索要空间时,可能涉及到多个桶的使用,如果使用桶锁,可能会导致反复的加锁解锁,降低整体效率。因此我们使用一把公共锁处理Page Cache。
如何划分Page Cache传递给Central Cache的空间?

1 | |
如何解决最开始内存池为空的问题?
- 从堆申请空间,利用地址计算出_pageId等信息,并进行复用。
1 | |
其他问题
当Page CaChe处理Central Cache的内存时,要不要解开Central Cache的桶锁
- 需要,因为可能存在竞争的一个线程是来归还内存的。可以提高内存利用率。
解决内存碎片:
如果central cache中span的 usecount等于0说明切分给thread cache小块内存已经不被使用,则central cache把这个span还给page cache,page cache通过页号,查看前后的相邻页是否空闲,是的话就合并,合并出更大的页,解决内存碎片问题
Static和TLS
只能在当前文件内可见,
TLS一定程度上依赖于此。并且每个线程使用TLS是不会由于进程切换而改变的。通过TLS,每个线程无锁的获得自己专属的所需对象。